|
存储,即选用合适的存储媒介来存储爬取到的结果,Python 爬虫的数据存储模式有很多中,有json,mongodb,mysaql,csv,我本人了解这几个比较常用的。我们从最容易了解的csv开始。 CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用来存储表格数据,包括数字或者字符。 csv的使用很广泛,很多程序都会涉及到 csv的使用,但是 csv却没有通用的标准,所以在处理csv格式时常常会碰到麻烦。因此在使用 csv时一定要遵循某一个标准,这不是固定的,但每个人都应该有一套自己的标准,这样在使用 csv时才不会犯低级错误。 它比Excel文件更加简洁,XLS文本是电子表格,它包含了文本、数值、公式和格式等内容,而CSV中不包含这些内容,就是特定字符分隔的纯文本,结构简单清晰。所以,有时候CSV来保存数据是比较方便的。 简单的例子: import csv
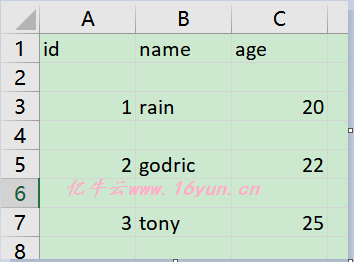
with open('data.csv', 'w') as f: writer = csv.writer(f) writer.writerow(['id', 'name', 'age']) writer.writerow(['1', 'rain', '20']) writer.writerow(['2', 'godric', '22']) writer.writerow(['3', 'tony', '25']) 运行结束后会生成一个data.csv的文件,此时数据就成功写入了。直接以文本形式打开,会显示如下内容: id,name,age
1,rain,20
2,godric,22
3,tony,25 可以看到写入的文本默认以逗号分隔,调用一次writer()方法就会写入一行数据。使用Excel打开: 获取单个表格的更简便的方法 如果你有很多 HTML 表格,且每个都要转换成 CSV 文件,或者要将许多 HTML 表格汇总到一个 CSV 文件,那么可以把这个程序整合到爬虫里。但是,如果这种事情你只需要做一次,那么更好的办法是复制粘贴。选中 HTML 表格内容然后复制粘贴到 Excel 里,就可以另存为 CSV 格式,不需要写代码就能搞定! 最后让我们来总结一下使用 csv库的注意事项: 打开文件时要 注意模式 读用 r,写用 w 打开文件时要设置 newline=''(空字符) 打开文件时要指定编码打开,写入时也一样 如果设置过分隔符就要一直保持,读写时的分隔符必须一致 csv不会检查格式(虽然有个 strict模式,但 strict模式下也不会对格式进行检查),写入文件时一定要注意格式
|  |Archiver|手机版|小黑屋|IT帮社区
( 冀ICP备19002104号-2 )
|Archiver|手机版|小黑屋|IT帮社区
( 冀ICP备19002104号-2 )


 发表于 2020-5-18 17:38:52
发表于 2020-5-18 17:38:52