|
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。 前言 我看到最近几部电影很火,然后查了下在豆瓣是上的排行榜数据,发现豆瓣里面有各种经典和热映电影的排行榜,于是突发奇想的想爬取下豆瓣电影的排行榜,好像可以用一下最近学的东西实现我的需求,学习了正则表达式之后,想着要感受一下它在爬虫里面的效果和优缺点。 爬取内容:电影排行(rank),名称(name),演员(actor),评分(score),评价(comment),引用(quote) 步骤 ## 利用正则表达式爬取豆瓣电影排行(rank,name,actor,score,comment,quote)# 导入库,做好存储预备工作import requestsimport reimport timeimport csvf = open('C:/Users/home/Desktop/3.csv','w+',encoding='utf-8',newline='')writer = csv.writer(f)writer.writerow(['rank','name','actor','score','comment','quote'])# 加入请求头,利用requests请求,爬取数据headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36' }url = 'https://movie.douban.com/top250'# 利用findall方法筛选所需数据,将该步骤封装为函数get_infodef get_info(url): res = requests.get(url, headers=headers) ranks = re.findall(' <em class="">(.*?)</em>',res.text,re.S) names = re.findall('<span class="title">(.*?)</span>.*?<span class="title"> / (.*?)</span>.*?<span class="other"> / (.*?) / (.*?)</span>',res.text,re.S) actors = re.findall('<p class="">.*?(.*?) (.*?)...<br>.',res.text,re.S) scores = re.findall('<span class="rating_num" property="v:average">(.*?)</span>',res.text,re.S) comments = re.findall('<span property="v:best" content="10.0"></span>.*?<span>(.*?)人评价</span>.*?</div>',res.text,re.S) quotes = re.findall('<span class="inq">(.*?)</span>',res.text,re.S) for rank,name,actor,score,comment,quote in zip(ranks,names,actors,scores,comments,quotes): writer.writerow([rank,name,actor,score,comment,quote])# 设循环语句,循环爬取数据,每次中断2s防止被绊if __name__ == '__main__': urls = ['https://movie.douban.com/top250?start={}&filter='.format(str(i)) for i in range(0,250,25)] for url in urls: get_info(url) time.sleep(2)
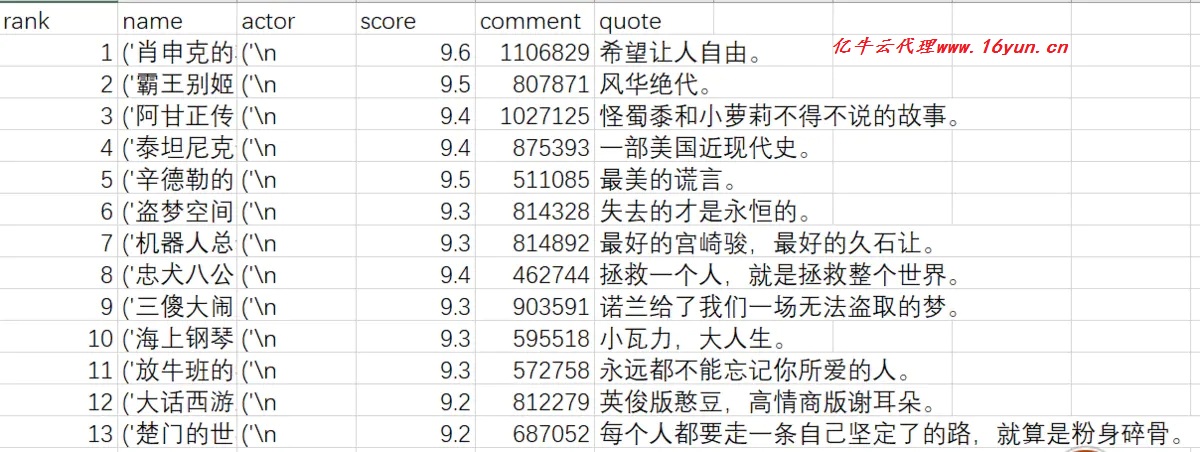
爬取结果 这是一个很简单的应用,也是自己学习之后的实践,在这个例子中,我是用到正则表达式来实现的,还有其他方法,而且可能简单,比如BeautifulSoup,XPath等方法,用在更加复杂的爬虫项目里面,需要的知识更多,方法更严谨,还需学习学习!
|
 |Archiver|手机版|小黑屋|IT帮社区
( 冀ICP备19002104号-2 )
|Archiver|手机版|小黑屋|IT帮社区
( 冀ICP备19002104号-2 )


 发表于 2020-5-25 17:40:31
发表于 2020-5-25 17:40:31