|
企查查的反爬机制不仅非常完善而且是很严厉的,用selenium登陆的时候发现目标网站能检测到并弹出滑块,然后无论怎么滑动都通过不了,而且还会封账号。在经过一番搜索后发现很多网站对selenium都有检测机制,如检测是否存在特有标识 。 我们用最基本策略就是挂上代理,这里我们配置的是亿牛云的动态转发,代码示例如下: # -*- coding:UTF-8 -*-import timeimport refrom datetime import date, timedeltafrom selenium import webdriverfrom selenium.common.exceptions import NoSuchElementExceptionfrom selenium.webdriver import ActionChainsfrom selenium.webdriver.chrome.options import OptionsTB_LOGIN_URL = 'https://login.taobao.com/member/login.jhtml'CHROME_DRIVER = '/usr/local/bin/chromedriver' # Windows和Mac的配置路径不一样class SessionException(Exception): """ 会话异常类 """ def __init__(self, message): super().__init__(self) self.message = message def __str__(self): return self.messageclass Crawler: def __init__(self): self.browser = None def start(self, username, password): print("初始化浏览器") self.__init_browser() print("切换至密码输入框") self.__switch_to_password_mode() time.sleep(0.5) print("输入用户名") self.__write_username(username) time.sleep(2.5) print("输入密码") self.__write_password(password) time.sleep(3.5) print("程序模拟解锁") if self.__lock_exist(): self.__unlock() print("开始发起登录请求") self.__submit() time.sleep(4.5) # 登录成功,直接请求页面 print("登录成功,跳转至目标页面") self.__navigate_to_target_page() time.sleep(6.5) print("解析页面文本") crawler_list = self.__parse_page_content(); # 连接数据库并保存数据 print("保存数据到mysql数据库") self.__save_list_to_db(crawler_list) def __switch_to_password_mode(self): """ 切换到密码模式 :return: """ if self.browser.find_element_by_id('J_QRCodeLogin').is_displayed(): self.browser.find_element_by_id('J_Quick2Static').click() def __write_username(self, username): """ 输入账号 :param username: :return: """ username_input_element = self.browser.find_element_by_id('TPL_username_1') username_input_element.clear() username_input_element.send_keys(username) def __write_password(self, password): """ 输入密码 :param password: :return: """ password_input_element = self.browser.find_element_by_id("TPL_password_1") password_input_element.clear() password_input_element.send_keys(password) def __lock_exist(self): """ 判断是否存在滑动验证 :return: """ return self.__is_element_exist('#nc_1_wrapper') and self.browser.find_element_by_id( 'nc_1_wrapper').is_displayed() def __unlock(self): """ 执行滑动解锁 :return: """ bar_element = self.browser.find_element_by_id('nc_1_n1z') ActionChains(self.browser).drag_and_drop_by_offset(bar_element, 800, 0).perform() time.sleep(1.5) self.browser.get_screenshot_as_file('error.png') if self.__is_element_exist('.errloading > span'): error_message_element = self.browser.find_element_by_css_selector('.errloading > span') error_message = error_message_element.text self.browser.execute_script('noCaptcha.reset(1)') raise SessionException('滑动验证失败, message = ' + error_message) def __submit(self): """ 提交登录 :return: """ self.browser.find_element_by_id('J_SubmitStatic').click() time.sleep(0.5) if self.__is_element_exist("#J_Message"): error_message_element = self.browser.find_element_by_css_selector('#J_Message > p') error_message = error_message_element.text raise SessionException('登录出错, message = ' + error_message) #跳转至目标页面 def __navigate_to_target_page(self): pass # 解析网页数据 def __parse_page_content(self): pass #保存数据 def __save_list_to_db(self, crawler_list): pass def __init_browser(self): """ 初始化selenium浏览器 :return: """ options = Options() # options.add_argument("--headless") prefs = {"profile.managed_default_content_settings.images": 1} options.add_experimental_option("prefs", prefs) options.add_argument('--proxy-server=http://127.0.0.1:9000') options.add_argument('disable-infobars') options.add_argument('--no-sandbox') self.browser = webdriver.Chrome(executable_path=CHROME_DRIVER, options=options) self.browser.implicitly_wait(3) self.browser.maximize_window() self.browser.get(TB_LOGIN_URL)#执行命令行Crawler().start('username'), 'password'))
程序运行后发现还是很卡,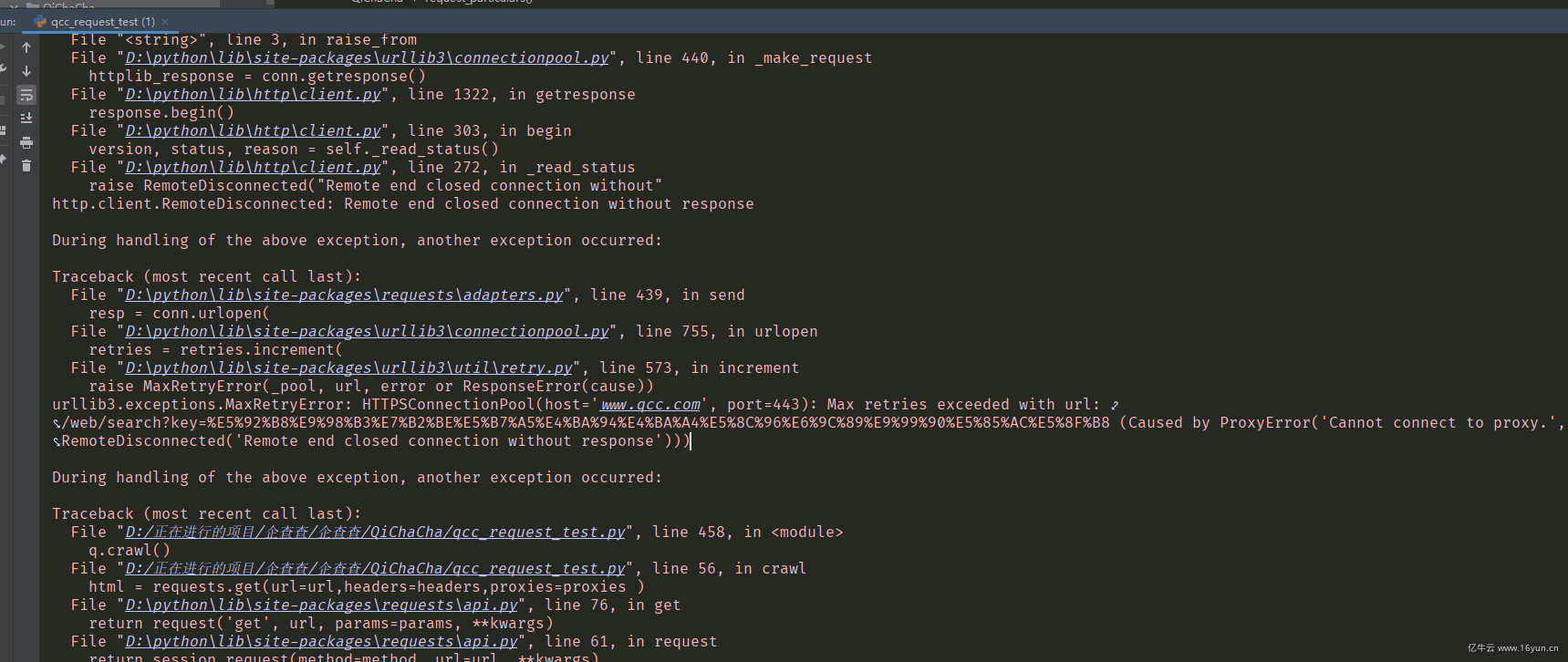 经过分析,也可能目标网站并不是封代理ip,而且封账号,所以这样的网站是不能靠挂代理解决的,大家要是对企查查有解决的好办法可以一起交流学习下。
|  |Archiver|手机版|小黑屋|IT帮社区
( 冀ICP备19002104号-2 )
|Archiver|手机版|小黑屋|IT帮社区
( 冀ICP备19002104号-2 )


 发表于 2021-5-27 16:30:05
发表于 2021-5-27 16:30:05


